11 - Crowdsourcing Marketplace
Creating training data is a labor-intensive task. Fine-tune the training data definition yourself and then scale-up by outsourcing to remote workers.

Remote workers are often recruited to complete labor-intensive tasks like building training datasets. Amazons Mechanical Turk (MTurk) is the leading platform for this task. Work is defined in human intelligence tasks (HITs) and range in length, complexity and compensation.
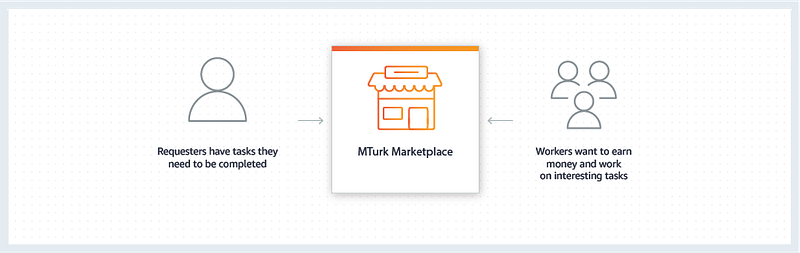
MTurk mechanism (source)
Outsourcing work is great, but there are limits. While MTurk is often considered a cheap solution to data collection, there are actually many hidden costs. You must be very explicit in defining HIT descriptions. A lot of effort is required for managing the project and monitoring quality control.
It is recommended to start labeling yourself. You will experience a lot of trial-and-error in the labeling-scheme and the annotation- and tag-definitions. Only proceed if you have confidence in your labeling scheme and applied this for building a Proof-of-Concept. So, experiment and fine-tune the training data definition yourself and then scale-up to MTurk.
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.