13 - Rulebased Training Data
Programmatically build training datasets by defining heuristic rules which are used in functions for labeling training data.

A solution to scale up your training data is by programmatically building training datasets without manual labeling. The idea is to define heuristic rules which are used in functions for labeling training data.
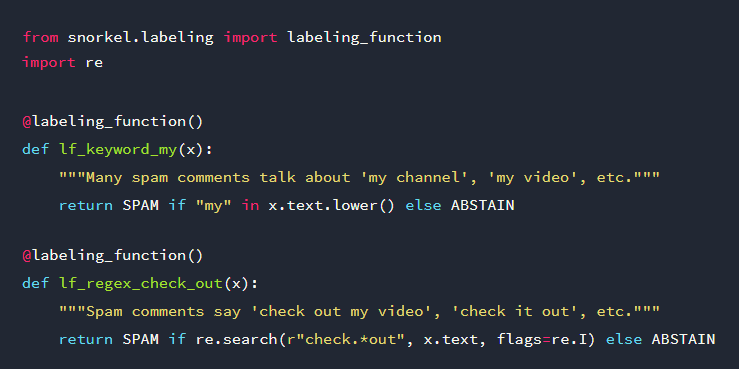
Since the labeling functions have unknown accuracies and correlations, their output labels may overlap and conflict. By using a model to automatically estimate the accuracies and correlations, reweight and combine the labels, you can produce a final set of clean, integrated training labels.
The goal is to use the resulting labeled training data points to train a machine learning model that can generalize beyond the coverage of the labeling functions. This Python tutorial uses Stanford’s Snorkel library for this purpose. It’s quite successful, because the team is building a business solution around the concept.
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.