55 - Topic Modeling
Dividing a set of vectorized documents into N unsupervised topics by determining how similar vectors for a specific topic should be, and how many topics should be distinguished.

To divide a set of documents into N unsupervised topics, the documents should be represented by compact vectors. Term Frequency * Inverse Document Frequency (TF-IDF), Latent Semantic Indexing (LSI) and Latent Dirichlet Allocation (LDA) are the best-known Vector Space Model algorithms for transforming a document into a vector.
The critical step in Topic Modeling is to determine how similar these vectors should be, which documents belong to a specific topic and how many topics should be distinguished. In most libraries you have to define how many topics (clusters) the algorithm should generate.
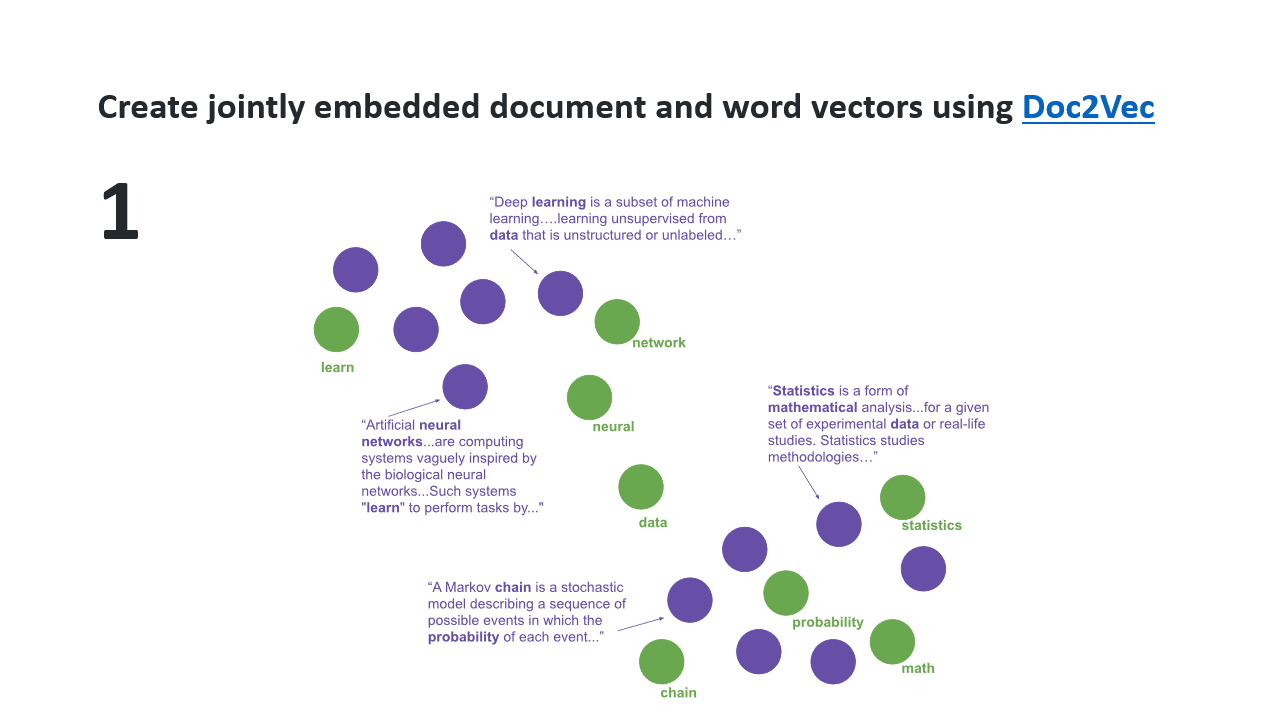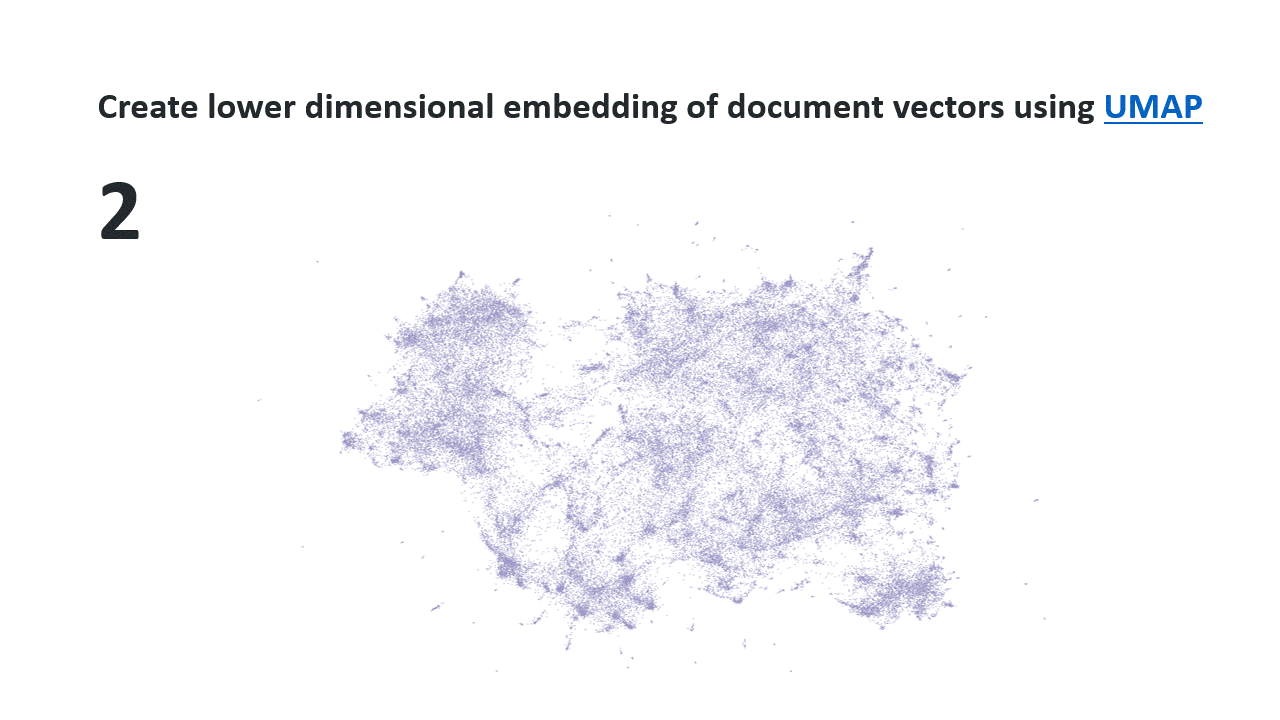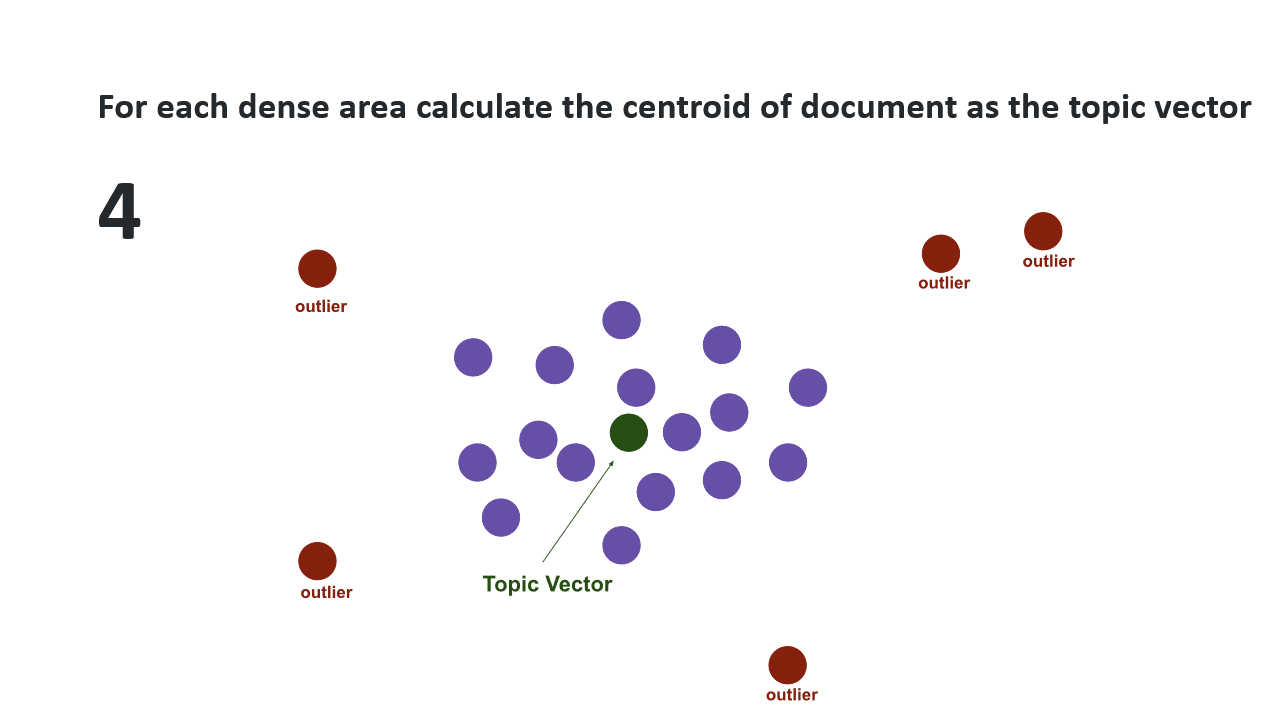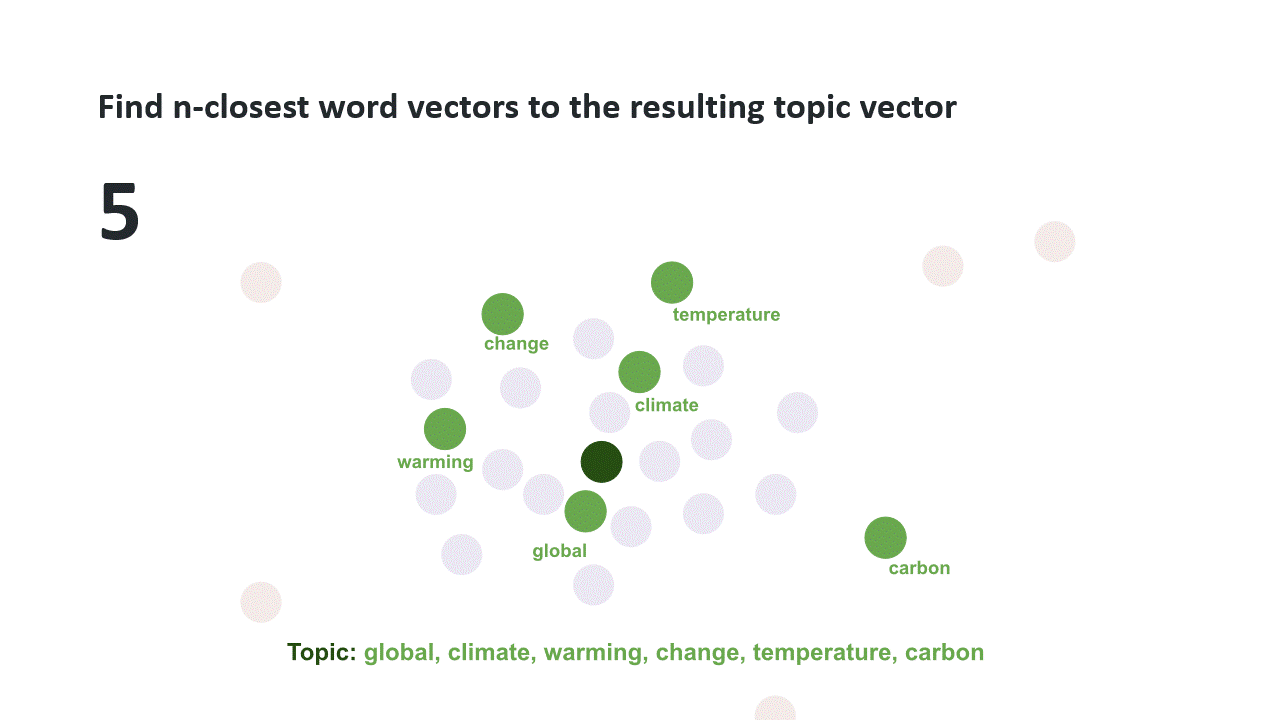
However, the library Top2vec automatically reduces the number of dimensions and finds dense areas in this decreased space. So, it determines the number of topics for you. You can prune this number of topics by iteratively merging each smallest topic to the most similar topic until you reach your target number. It also combines document vectors and word vectors to determining topic(vector)s and their most important words.
Another informative tool that should be mentioned is pyLDAvis, which is a library for interactive topic model visualization (demo).
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.