44 - Evaluating Models
Evaluating the quality of a Language Model should be done by comparisons based on the right metrics for your model type.
To evaluate the quality of a Language Model, it should be compared based on some score. For supervised models, like a text classification model, it will be easy to evaluate a model with metrics like precision, recall, accuracy and F1-score. For unsupervised models, like Natural Language Generation models, there are metrics like BLEU, ROUGE, METEOR and GLUE for extrinsic evaluation and Perplexity as an intrinsic evaluation.
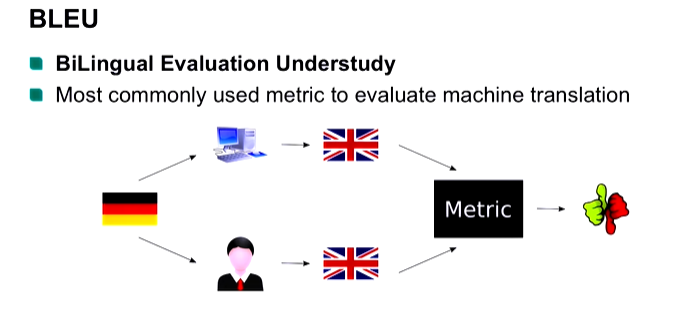
BLEU is a popular word-overlap metric and compares n-grams between a candidate text and a reference text. Unfortunately, it is unable to capture semantics and can lead to poor scores even for appropriate response. BLEU is popular for evaluating machine translation models.
The GLUE (General Language Understanding Evaluation) benchmark is model-agnostic, so any system capable of processing sentence and sentence pairs and producing corresponding predictions is eligible to participate. It has a lot of data sets for several genres and several techniques like coreference resolution, sentiment analysis and question answering. And it is used with a leaderboard. So people can use the data sets, and see how well their models perform compared to others.
You can calculate these metrics with the NLG-eval package or go to Huggingface for an overview and explanation of several metrics.
Perplexity is an intrinsic evaluation method. It’s not as good as the extrinsic metrics, but is useful to quickly make a comparison to the language model itself (e.g. for LDA) and not taking into account the specific task it’s going to be used for. Perplexity is the inability to understand something. A low perplexity indicates the model is good at predicting the sample. SOTA (state-of-the-art) perplexity for a language model is 11.
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.