41 - Meta-Info Extractor
Extracting text from a file should be accompanied with the extraction of meta-information.

If a document is considered to be information , its title, URL, publishing date, last-editing date, extraction-timestamp, author, filetype and subject are examples of meta-information.
When you extract text from a file with Apache Tika, it will also provide the meta-information. When you use the Twitter API, you can also get the meta-information of a tweet. A Tweet can have over 150 attributes associated with it.
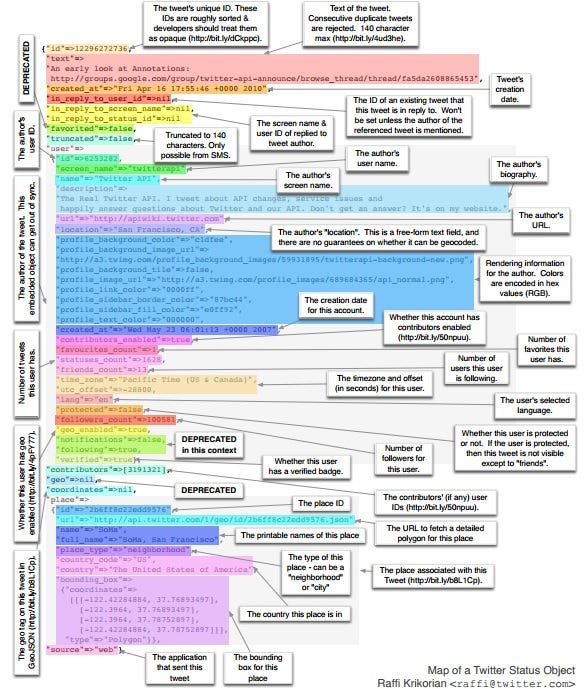
Once you extracted the meta-information, it’s interesting to combine it with info extracted from the text. For example, the publication date from the document can be used as reference date for temporal expressions. You can declare the date for the word ‘yesterday’ based on the publication date.
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.