25 - Rulebased Phrasematcher
Finite size lookup tables might inspire your to build rulebased searches, especially when semantic info like lemma’s and POS- and Dependency tags can be used in the search pattern.

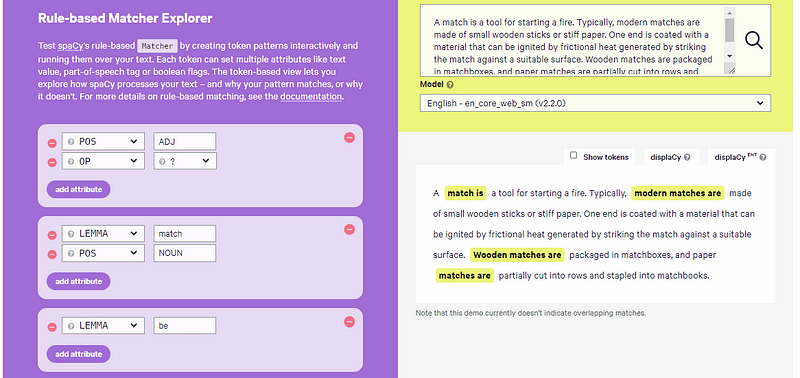
A lot of text analytic analysis start with searching a list of words or phrases. If you have a problem of finite size where a lookup table (gazetteer) is sufficient, then a matcher might be the solution. This task has evolved over time. It is still rulebased, but smarter. Missing search hits will be prevented by looking at tokens instead of raw text.
For example, all the double spaces and tabs between words will not influence the search results. Also searches can be defined on a more semantic level. For example one can search for all forms of a verb, just by defining the lemma (base form) of the verb. Or search for the lemma of a noun and you will get all the single and plural values of this noun.
Performance is also important when searching for a large list of words against a large corpus. Flashtext has an algorithm in python that has a gigantic performance gain compared to regex searches.
spaCy has a Token Matcher for detailed searches on (semantic) properties of (multiple) tokens and a Phrase Matcher for very long lists of (multiple) words.
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.