06 - Text and File Scraping
The lack of a Corpus or API requires you to scrape your textual data or files from the web. Overcome the challenges of IP-blocking, cookie walls, request headers and js-websites.

If you need information from the web, but there is no API or other structured way of retrieving the data, then you might want to scrape textual data, or files.
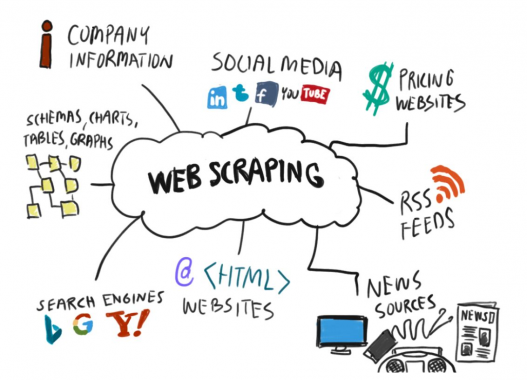
However, there are some challenges. When visiting a lot of webpages in the same domain in a short time there’s a good chance your IP-address gets blocked by the server. In preventing this you probably want to handle request headers, manage cookies, automatically login, handle popups and browse javascript-generated websites in ‘headless’ mode.
After getting access to the page source of the webpage one has to define the logic to extract values from HTML. For example, retrieve all the text from the news article, but not the text from the advertisements or menu buttons.
Very popular python packages to get started with building successful scrapers are: Scrapy, Beautiful Soup, Urllib and Selenium.
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.